The number of hits to this blog has skyrocketed, from an average of 0 hits per hour to 27 hits per hour. I guess this means that it’s getting real: the book is coming out this summer! See the AMS Bookstore for the latest details and ordering information. Thanks to the American Mathematical Society for their great efforts in production and marketing. I worked with the production team on a cover design, and here it is…
Final cover design!
What remains, on my side, are final details for production. I’ll be receiving the proofs in the next day or two, which gives me a few weeks to check that everything is in good shape. It also gives me time to make some important minor edits (e.g., changing “any” to “every”, and being more careful when talking about sets) — thanks to the reviewers for the many constructive suggestions. The bulk of the work will pass to the AMS teams who are working hard to publish this book.
I haven’t posted on this blog for a long time, and I don’t plan to post here in the near future. I will leave the blog up on the internet though, and I’ll have more to say when I see the text in hardcover for the first time.
Over the summer, I plan on developing a website to accompany the book: that’s where I hope you’ll find Python notebooks, interactive visualizations (developed with d3.js), the inevitable errata, and more.
Thank you for following, and I hope you enjoy the book!
I’m back in Santa Cruz again, where the Fall quarter just began. Fall in Santa Cruz means warm weather, busy surf on weekends, and time to Git Teaching!
Overhead surf wrapping around the Lane, September 24, 2016.
In the programming community, Git and GitHub are popular tools for version control and sharing. As a pair, they accelerate project development and collaboration. I didn’t use them for writing the book (regrettably), but I decided to use them to create and share teaching materials. Thanks to the Udacity course on Git/GitHub, I was able to pick up the basics in about 5 hours. So what do I mean by using Git for teaching? I now have two public Git repositories on GitHub.
Git Lesson Plans
The first contains my lesson plans for the quarter. Since this is at least the 10th time I’ve taught this material, I usually prepare for class by scribbling down a half-page of notes to myself. I wanted something almost as quick as scribbling, but which would be easy to share with the world (and perhaps to polish later). So I made a little lesson plan template, made 20 copies (for 20 lectures), and put it up on GitHub. Using Markdown is almost as quick as scribbling, since I can edit it right in my web browser at GitHub (then print a copy for class). You can see my first lesson plan, from last Thursday.
Git Assessment Generator
The second repository is more ambitious. Since I’m teaching 70+ students, I want to create quizzes with some randomly generated questions. I considered ad-hoc solutions with PythonTex, started poking around, and realized that there isn’t a sufficiently general Python package for creating and rendering questions for math assessments. Webwork has PGML and MathObjects. But this is PERL-based, oriented towards calculus and online assessments, and not as flexible as I wanted in the creation and rendering of questions and answers. I found myself a bit over my head in programming, but a contribution from Janis Lesinskis got things off the ground. His began the project at his GitHub repository. I forked the project at my repository and added code for flexible Python-generated questions. It’s not close to ready for the public, but I think Janis set up a great foundation on which I can build something useful. I’ll build it further as I write the first quizzes for my class, and I hope to leverage the power of LaTeX, Python, and the Jinja for templating.
How are these related to the Illustrated Theory of Numbers?
The Illustrated Theory of Numbers is a text, designed primarily for print media. It is not open-source, though I am sharing some excerpts and some methods I used to create it. On the other hand, I want to build an open community to share resources related to teaching number theory — lesson plans, assessments, and resources outside of the text I’m writing. My own lesson plans might be helpful to instructors who wish to teach out of the book I’m writing, and so I’m happy to post them for the world to see. Similarly, writing quizzes is time-consuming, and I think that sharing assessments is a good way to build a community.
Unlike the calculus textbook industry, I don’t want to put out new editions every year, charge for online accessories, etc.. I hope that by the time the book appears in print (mid-2017?), students and faculty can find a great set of free complementary resources online.
Today I received a very nice package from the AMS — a complete color printout of a draft of the book! This means it’s time to proofread, and think of all the things I should have done along the way.
Feline proofreading. The color blue!60 looks very purple to me. The cat looks orange!1000 as usual.
So here is a retrospective look at what I should have done.
Created a stylesheet as I was writing. For example, when abbreviating circa (as in Euclid lived c.300 BCE), is there a space as in “c. 300” or not as in “c.300”. I’ll look it up… but my life would have been easier if I had kept a running list of style details for consistency throughout the manuscript. Credit goes to Ellen Muehlberger for this advice — when I told my wife about this problem, she said that her advisor (E.M.) told her to maintain such a stylesheet throughout her dissertation. Great advice!
Used a version control system throughout. I just took the Udacity course on Git and GitHub yesterday (better late than never). It’s an excellent quick class, and I’ll be using GitHub for producing a webpage for the book, sharing teaching materials, etc.. Unfortunately my current book files are organized like my camping gear… randomly stashed in large not-quite-clean tubs.
Considered CMYK color issues from the outset. I had read and heard about color issues before, but didn’t do anything about it. So now I have a large book, and of course the colors look great on a monitor (in RGB) and varying stages of terrible in print (in CMYK). Fortunately, I have been using xcolor throughout, which gives me precise control over colors in the CMYK (or any other) colorspace. I was a bit surprised at how different things ended up in print. For example, a standard red corresponds to 0% Cyan, 100% Magenta, 100% Yellow, 0% Black in CMYK space. I wanted to desaturate the red when filling large areas; the xcolor setting red!50 yields the result 0% Cyan, 50% Magenta, 50% Yellow, 0% Black, which makes sense. But on paper, this looks distinctly orange, in a sort of carrot-left-in-the-freezer-too-long way. Similarly blue turns pale purple as blue!50. The solution is fun, if a bit time-consuming. I printed a CMYK color chart which I found via stackexchange, asking the local print shop to use their nicest inkjet and book-quality paper. I’m using this printed color chart to choose my colors now. So, instead of using a command like blue!50, I’ll define my own color (blueB perhaps) as 60% Cyan, 10% Magenta, 0% Yellow, 7% Black, and use this wherever I used blue!50 before. I’ll probably give the local print shop some business with color experiments over the next month. There’s really no way for me to match what the eventual offset printer will do, but I’m hoping to get as close as possible.
As of 9am this morning, the Illustrated Theory of Numbers is under contract with the American Mathematical Society! So now is a good time to write about the process of choosing a publisher and settling on contract details. My sample size of book contracts is now 1, so I wouldn’t extrapolate too much from my personal experience.
Why the AMS?
I spoke with two other publishers along the way, and ended up with the AMS for a few reasons. First, the AMS Mission is “To further the interests of mathematical research, scholarship and education, serving the national and international community through publications, meetings, advocacy and other programs.” The AMS(registered as a 501(c)(3) not-for-profit) represents the research and educational interests of mathematicians like myself — and I doubt that this is the case for the large textbook publishers (e.g., Pearson, McGraw Hill, Elsevier).
Other reasons that I am excited to work with the AMS are the following:
I believe that the production quality of the book will be good, while the price will be about half that of the market-leading textbooks in elementary number theory.
The editor, Sergei Gelfand, and others were at all times professional and responsive and helpful.
The AMS seemed to understand my goals for the book, and their goals and mine seem very close.
The AMS was responsive to my pickiness about design and layout, while reasonable about their own capabilities.
I trust the AMS as an organization — that if something goes awry, I have more support than strictly provided by the contract.
Negotiables
I consider some of the illustrations in the book to be a form of artistic output. I may adapt some of them and create posters, clothing, mugs, etc.. So it was important to me that the AMS maintain the rights to publish the book and derivative works, except that I would maintain the right to produce (and possibly sell) artistic works. This is described in the contract.
I have some worries about electronic distribution of the text. As a reader, I appreciate that I can download whole books from Springer through my library. But as an author, I don’t really want a downloadable publication-quality PDF of the whole book to circulate freely on the internet. I think that some texts (e.g., the vast majority of research literature, publicly funded research and education projects) should circulate freely or very close to freely. But since the Illustrated Theory of Numbers is a personal project, not funded by the NSF or anyone else, and contains original artwork, I think it’s fair to protect copyright a bit. I also hope to make enough money for a little vacation too.
I’m not 100% satisfied with the language around electronic distribution in the contract, but I think it’s about as good as it gets. Due to the rapidly changing landscape of electronic publication, the contract gives the publisher flexibility. One place where I requested a change was in electronic sales upon termination of the agreement. If the contract is terminated at some stage, rights to sell e-books also terminate shortly after. Although the language is not entirely to my satisfaction, I am placing my trust in the AMS to represent my interests as an author and their financial interests in protecting copyright.
Royalties with the AMS are based on a percentage of “net income”. This (apparently standard) term refers to the amount of money the AMS takes in from selling the book, minus some costs for returns. It’s thankfully not the same as “net profit” — the costs of production are not deducted. I found the percentage reasonable and generous.
In the Illustrated Theory of Numbers, the pictures serve different purposes. Some lend geometric insight to proofs. Others display logical flow. Others render an abstract concept. This post is about those which are data visualizations.
Using the term “data visualization” automatically increases web traffic, but I’m not just doing it for the hits. Instead, I think it’s time that the best data visualization practices are directed towards the most interesting data in number theory: the prime numbers being the prime example. While the data visualization community typically studies people and places and money and the natural world, the Illustrated Theory of Numbers gets its data from numbers themselves. It is one of the fascinating things about number theory that the data is entirely deterministic while at the same time obeying heuristics for random variables.
In this spirit, I’ve provided two drafts of a data visualization below, displaying the distribution of prime numbers up to 5 million. I’ll explain the editing process that led me from left to right.
My goal in this image is to provide the reader with a sense of the microscopic irregularity and the macroscopic regularity of the prime numbers. In the left column, the prime numbers are thick bars (10 points, I think). Each column displays a range of prime numbers: the first displays primes up to 50, the second the primes up to 500, etc.. The rightmost column displays the primes up to 5 million. In some ways, this is the simplest kind of data set — a one-dimensional distribution.
From the beginning, I decided on this basic layout of columns, so that by the rightmost column the image would appear smooth, and gradually getting lighter towards the top as the primes spread out. The numbers which represent primes on the far left are replaced by densities on the far right. A number near 5 million has about a 6.5% chance of being prime.
I made a lot of changes to this image, starting with the draft on the left (from a few years ago) and ending at the draft on the right (a few weeks ago). First, I pushed the prime number labels onto the bars. There might be some printing/clarity risks with white text on black bars, but it gets across the idea that the bars are the prime numbers and it reduces the chance of confusion that the same “ticks” apply to all columns.
In that spirit, I narrowed and separated the columns. This, I think, lightens the whole page, saves ink, and increases clarity. The red lines now indicate how each column is effectively contained in a tenth of the column to its right. I’ll admit there’s a bit of influence from the cover of Tufte’s Visual Display of Quantitative Information, though the subject matter is completely different. I hope the red lines also break the tendency to scan directly left-to-right, and indicate how data is squeezed into shorter intervals.
Also lightening the page, I changed the shading in columns 3-6. In the first two columns, solid black bars are used to represent prime numbers. But in columns 3-6, a shade of gray is used according to the density of primes in each bin. Among the numbers between 4000 and 4499, there are 60 prime numbers. Since 60/500 = 12%, I used a line segment at 12% black in the later draft. (With TikZ, this is accomplished by setting the color to black!12).
At first I was concerned that this would be too light, and I’ll see how it all looks when it’s printed professionally. But on the Ricoh printers here, the result looks good — even at 6.5% black (the density around 5 million), the gray is easily distinguishable from the white paper. And this fits with the principle of “smallest effective difference” described in Tufte’s Visual Explanations. It’s a bit hard (though not impossible) to see the primes spread out, as their density goes from 8.5% to 6.5% in the rightmost column. But that’s also part of the honest representation — it would be dishonest to the data to exaggerate the image to make the primes appear to spread out more quickly. The table of densities at the far right exhibits the gradual spreading unambiguously with numbers.
A note to the reader — the images tend to render with horizontal stripes on a computer monitor! Another reminder to print on a regular basis.
There’s probably a bit more tuning to do before publication. The primes deserve the effort.
To keep it short, without excuses: I’m back to writing!
I’m moving back to the United States from Singapore this summer. What this means, practically speaking, is that I have a lot of writing time between now and mid-September. During the 5-6 weeks when my life’s possessions are in a shipping container, I’ll be on writing retreat at an undisclosed location below.
I’m committed to having a first draft for the referees by June 4, and a final draft by mid-September, and everything is going according to schedule so far. I’ll update this blog periodically over the summer… so stay tuned for more shortly.
Like most blogs, the Illustrated Theory of Numbers blog went on a long hiatus. Unlike most blogs, this one has returned! Really, there has not been too much to show over the past few months, but I’ve gotten back to work on Part II of the book, covering binary quadratic forms (including all discriminants, Pell-like equations, a bit on SQUFOF factorization perhaps, the class number and the “Siegel bound”). This might strike the experts as a bit out of order — where is modular arithmetic already? — but I’m sticking with “global” number theory until Part III of the book. Of course, some readers might skip Part II and go directly to Part III, but I hope they will return to Part II to learn Conway’s beautiful “topographic” approach to binary quadratic forms.
I was heavily influenced by Conway’s visual approach to binary quadratic forms, found in Chapter 1 of “The (sensual) Quadratic Form.” It’s amazing how far you can go with his topographs. I think I can go through reduction theory, symmetries (a.k.a. orthogonal groups), and finiteness of the class number, without ever needing to multiply two matrices. As recent work of Savin and Bestvina illustrates, along with recent work of my PhD student Chris Shelley, Conway’s approach generalizes in interesting ways to binary Hermitian forms and beyond.
One thing I use often in Part II is the determinant. Fortunately, for two-by-two determinants, the geometry is relatively simple. Below is a two-page spread introducing the geometric interpretation of the determinant. A helpful bonus, presented in parallel, is the discrete version: Pick’s theorem for lattice parallelograms.
Two-page spread from Chapter 6. Click to enlarge.
From mathematical and design perspectives, I like the idea of presenting parallel proofs in visual parallel on opposite pages. The left displays a theorem in continuous Cartesian geometry; the right displays a theorem in discrete geometry. The idea of dissection is the same, but the discrete version requires a bit more care.
I’m not exactly sure what to call the theorem on the right side of the page. It certainly falls under the purview of Pick’s Theorem but really, someone must have proved it before Pick, at least for parallelograms! I wouldn’t be surprised to see it in the work of Gauss or Eisenstein, if not earlier. Unfortunately, my German is not so good (nicht so gut?), though I can recognize the frequency of “Gitterpunkt” (grid-point) and “Gitterpolygon” (polygon with vertices on grid-points) in 19th century sources. Any reader who can find an earlier reference for Pick’s theorem, even for parallelograms (rectangles don’t count on their own!) gets an acknowledgment in the book!
The utility of Pick’s Theorem is the following — it gives a cute geometric proof of the following fact well-known to algebraists: A pair and of integer vectors forms an integer basis of if and only if . Indeed, a grid-parallelogram of area one cannot cover any grid-points except its corners, by Pick’s Theorem. This avoids any mention of matrix inversion, for example.
From a design perspective, this two-page spread was a lot of fun (and a bit of work). A combination of \foreach and scoped \clip commands in TikZ allowed for the easy creation of dot-textures on the right page. Perhaps the toughest decision (and one that isn’t final) was the choice of four colors; they are called “pinkish,” “blueish”, “greenish”, and “orangeish” in my source file. Following some technical color-theory advice, I worked with a color tetrad — literally a rectangular arrangement in the HSV color wheel, converted for LaTeX via the xcolor package. Analogous regions, such as the triangles, are in the nearby colors blue and green. Less saturated colors are on the left page, where there are large regions of solid color. Fully saturated colors are on the right page, where the colors are in small dots. The real test of color will come when I print this out, along with another half-dozen copies with other rectangular tetrads of color, and see what looks the best.
Modern number theory begins with the integers, all those whole numbers, positive, negative, and zero. A few times, when teaching number theory, I began simultaneously with the integers, the Gaussian integers, and the Eisenstein integers. One pedagogical reason is this: if you spend the first few weeks of number theory class proving things that students “learned” by fifth grade, then students will not likely be excited. The Euclidean algorithm can excite students, but proving the existence and uniqueness of prime decomposition is — from the students’ perspective — proving something they already (think they) know. Number theory teachers can get flustered by this. “No!” they say, “You only think you know this! It needs to be proven. It’s really not trivial! Really! Pay attention!”
I think there are two important roles for the instructor at this stage. One is to guide the student to wiser ignorance, as in Plato’s Meno, where Socrates says “Is he not better off in knowing his ignorance?”. To this end, the instructor gives counterexamples, where irreducible elements (those that cannot be factored further) are not prime (do not satisfy the implication or ). The first counterexample that I learned was in the ring in which . The element is irreducible but not prime. I think this counterexample is natural to the number theorist and instructor — having a prior background in quadratic rings — but most unusual to the elementary number theory student. It also leaves the instructor having to convince the student that and and are irreducible. That is probably too difficult for the beginning student. A more elementary example occurs in Hilbert’s monoid of natural numbers congruent to one modulo . In this monoid (under multiplication), 9 is irreducible. On the other hand, but 9 does not divide 21. Another way to say this is that 441 factors into irreducible in two ways: and . So this Hilbert monoid might break the student’s false intuition that irreducible elements are prime, and that factorization must be unique.
Besides leading the student to wiser ignorance, the instructor should motivate the proof of existence and uniqueness of prime decomposition by demonstrating its application to number systems beyond the integers. To this end, one strategy is to simultaneously teach students the basic arithmetic of integers, Gaussian integers, and Eisenstein integers. I think students appreciate the details of proofs when they are proving something they don’t already “know”. Only those already devoted to pure mathematics will appreciate a proof of prior “knowledge”.
I have devoted Chapter 5 to a study of Gaussian and Eisenstein integers. I hope that some instructors will follow this chapter as they go through Chapters 2 and 3 to pique the interest of students. It is not technically necessary for what comes later, but Gaussian and Eisenstein integers are beautiful and important in their own right. I have always liked their kaleidoscopic symmetry, so I devoted an entire two-page spread to visualizations of Gaussian and Eisenstein primes.
Click to enlarge a two-page spread from Chapter 5
The pictures display the ramified, inert, and split primes in different colors, and the inert primes are displayed below on a number line to provide a scale. A fundamental domain is highlighted to exhibit the kaleidoscopic symmetry. Symmetry will reappear in the study of orthogonal groups of binary quadratic forms later, so it is good to see a few examples here. Hecke proved equidistribution of prime angles in the Gaussian context (and much more), in efforts to prove the infinitude of primes of the form . Thus I have drawn attention to the prime angles (with tick marks on the circumference) and the primes of the form (with parallel horizontal lines across the Gaussian plane). Analogously, I have drawn attention to the primes of the form in the diagram of Eisenstein integers.
Why else study Gaussian and Eisenstein integers? Some students think that generalization is a worthy goal for its own sake, but I prefer generalization with purpose. In Chapter 5, we use properties of Gaussian and Eisenstein primes to study properties of ordinary primes (infinitude of primes congruent to one modulo three and modulo four, and relations to primes of the form ). One “big picture” lesson of this book is that the study of larger and stranger number systems sheds light on the natural numbers. Exhibit G: The Gaussian Integers. Exhibit E: The Eisenstein Integers. Later on, quadratic rings, and the rings of modular arithmetic.
Why is the treatment of Gaussian and Eisenstein integers delayed until Chapter 5, instead of following my pedagogical advice to include them in the teaching of prime decomposition? There are two reasons. First, for shorter courses, I can imagine an instructor skipping Chapter 5. Second, Gaussian and Eisenstein integers connect the first part of the book (foundational properties of integers and rational numbers) to the second part of the book (on binary quadratic forms). By Chapter 7, we will study definite binary quadratic forms, and the Gaussian and Eisenstein integers will reappear in relation to the unique forms of discriminants and , respectively.
Fractions haunt elementary school teachers and occupy a disproportionate (1/2? 2/3? 15/17?) amount of time in math teacher professional development. Many college students arrive with a distaste for fractions; they are generally much happier talking about 3.4 rather than 17/5. There are a few likely reasons: it is much easier to work with decimals on a handheld calculator, and numbers are easier to compare as decimals rather than fractions.
But I like fractions, especially comparing them, and teaching fractions raises some important issues at the heart of mathematics. My two favorite fraction topics are the mediant fraction and kissing fractions. Both topics can be found in L. R. Ford’s article “Fractions” from the American Mathematical Monthly, vol. 45, no. 9 (Nov. 1938), pp. 586–601.
The mediant fraction is what happens every day when a child adds fractions the wrong way. The mediant of 1/3 and 1/2 is 2/5. Add the numerator, add the denominator — it’s a natural thing to try, but it doesn’t give you the sum. It gives you the mediant.
I wish more teachers would tell these children something like “What you’ve done isn’t adding the fractions, it’s something much more interesting. You’ve made the mediant fraction!”
What does this operation do? If you start with fractions with positive denominator, the output fraction is between the fractions you start with. But strangely, to a novice, the operation is really an operation on fractions, not on rational numbers. For example, the mediant of 2/6 and 1/2 is 3/8. But hang on a second — the mediant of 1/3 and 1/2 is 2/5, and 1/3 = 2/6, so how can this be?
This is one sign that the mediant isn’t an operation on rational numbers. It makes sense for fractions, but it depends on how the fraction is written. Further explanation is in the two-page spread below.
Click to enlarge a two-page spread from Chapter 4
I think teachers and students have trouble with this, and the obstruction is a poor understanding of semiotics. In other words, teachers and students do not adequately distinguish between numbers and how numbers are written. I made a common decision to use the word “fraction” to mean a written expression like “a/b”, and “rational number” to mean a number which can be described by a fraction. So “1/3” and “2/6” are different fractions, which mean the same rational number.
Why is this so important (besides the fact that the mediant is an operation on fractions)? I think this issue arises again and again. Eventually, I would guess most students think that numbers are decimal expansions. The number is the decimal expansion for most students. But this too is incorrect, leading to confusion when students or teachers hear that equals for the first time. Real numbers are not decimal expansions, nor are rational numbers fractions.
What about kissing fractions? Given integers , I say that kisses if or . I call this kissing, because two fractions kiss when their Ford circles kiss; kissing circles have been around for a long time, sometimes called tangent (touching) circles or osculating circles. Kissing fractions are the algebraic counterpart of kissing circles. Kissing fractions leads to more kissing, love triangles, and more. You’ll have to read Chapter 4 to find out. In case you think it is all a love-fest, Chapter 4 also contains material on the construction of the 17-gon and Dirichlet’s approximation theorem.
The mediant fraction and kissing fractions forced me to make a few notational decisions. Since the mediant fraction is not the sum, nor even really related to the sum, how should one write it? I use the “vee” symbol, as in
I think the “vee” symbol is good since it is symmetric (like the mediant operation) and it points to where the mediant ends up: right between the fractions you start with (if the denominator is positive).
For kissing, I couldn’t resist using the heart symbol, as in
since
Again the heart symbol is symmetric, and kissing is a symmetric relation. I hope I’m not getting carried away.
Now here is an activity for teachers who have made it all the way to the bottom of this blog post; an audience of 20-50 students is ideal. Write fractions on index cards; include all the reduced fractions between 0/1 and 1/1, with denominators up to 7 or 8 or 9. Your cards should include fractions like 2/5 and 3/7 and 1/4 and the like, one fraction per card.
Begin the activity by passing out the cards, and asking everyone with a card to stand up and line up in order of their (now personal) fractions. Quickly 0/1 and 1/1 will stand at opposite sides of the room. The activity usually takes a bit of time, as 2/5 and 3/7 have difficulty sizing each other up.
Next is a good opportunity to share how students compare fractions (common denominators, some weird butterfly technique, etc.).
Finally, have the students sit down, except for 0/1 and 1/1, who should stand at the corners of the front of the room. Ask them to add themselves, the wrong way (yielding 1/2), and ask 1/2 to stand between them. Then ask 0/1 and 1/2 to add themselves the wrong way, and ask the result (1/3) to stand between them. The students can take it from there… and they will remember the mediant fraction.
May the readers always understand signs, what they signify, and the difference between the two
A few months ago, I signed up for CS 101 at Udacity.com. This provided a wonderful introduction to the Python programming language. I was a pretty good Turbo Pascal programmer in high-school (early 1990s), but my programming since then had only involved short snippets in R (for statistics), SAGE (for research mathematics), and a bit of experimentation in javascript. With Python, I finally feel like I can playfully program again. I don’t have to worry about declaring various classes and main() things to control window objects. Programming is fun and simple again, even if I’m only using basic functional programming constructs.
Beyond the fun, Python is useful to me in two ways. First, SAGE is wisely built upon Python, so by learning Python I can do much more in SAGE. Second, by using a Python script to output TikZ code (nothing fancy – just some string manipulations), I can create data-dense PDF graphics with mathematical precision and quality typography and color. In other words, I have control over the graphics in my book. Any ugliness or error is my own. An example of a graphic created with a Python script, TikZ, and LaTex, is the opening graphic for Chapter 3 found below. The Sieve of Eratosthenese is visualized by different color-filters for each prime; multiples of 2 (starting with 4) are sieved with a red line, multiples of 3 with a blue line, etc.. The white-space remaining is prime. But to see the resulting primes at the end, I switch to black-and-white, and reverse the white-space of the primes to thin black lines for the primes. This allows the reader to see the distribution of primes between 2 and 577, irregular jumps and all. To label the vertical axis, I have minimized ink by placing labels only at primes; there is no use labeling 100, 200, 300, or placing additional tick marks, when the primes themselves can be used for the same purpose. Some fine-tuning might still be in order.
Click to enlarge the opening of Chapter 3
Now that I’ve become a Python advocate, I decided to go one step further and give Python code snippets throughout the Illustrated Theory of Numbers. You can see one in the margin on the right page. Inserting these snippets of code raises a lot of natural questions.
Why insert Python code instead of some universal pseudo-code? I am actively advocating Python, since I think the reader can benefit from learning Python, especially for future work in SAGE. Python is freely available and cross-platform. A C++ or Java programmer should be able to read Python code and translate easily enough into his or her native language. Also, Python is surprisingly fast for an interpreted language!
Why insert code at all? Why not just make a download freely available? I plan to eventually post all code in the book, fully commented and a bit expanded (for exception-handling). This way, readers will be able to download the python script, import it, and compute to their heart’s content. But personally, I find something satisfying about personally typing short snippets of code and then clicking RUN. Maybe it reminds me of programming 20 years ago. It might be an issue of pacing. I like writing on the chalkboard as I lecture, because it sets a deliberate thoughtful pace. When I type in a code snippet myself, I think about each line and why it works. I hope readers can enjoy typing and modifying the short (5-15 lines) code snippets on their own.
Don’t existing software packages work better? The answer is certainly yes. I have not given code snippets which are perfectly optimized. I have aimed for a balance between readability and speed. Hopefully a reader can learn Python by experimenting with these snippets, and a reader with programming background can understand exactly how the snippets work. Optimizing code requires a sacrifice in clarity, or much more space for explanation. On the other hand, I have tried to give code that works well in practice, for a student of number theory. You’re not going to factor 50-digit numbers with the included code, but 10-digit numbers should factor very quickly. The included sieve code makes a list of prime numbers up to 1 million in 0.07 seconds on my MacBook Pro. This should be a good start for students, and if they want more power they can use PARI and SAGE, or maybe NZMath if they want pure Python.
A final word about the code-snippets: I still have not figured out how to properly attribute them. The Sieve of Eratosthenes snippet on the 2-page spread above is based on code posted by Robert William Hanks to StackOverflow on July 27, 2010. I will be asking the publisher for suggestions on how to make code citations in a wildly open-source world, and I appreciate any suggestions along the way.







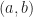 and
and  of integer vectors forms an integer basis of
of integer vectors forms an integer basis of 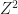 if and only if
if and only if  . Indeed, a grid-parallelogram of area one cannot cover any grid-points except its corners, by Pick’s Theorem. This avoids any mention of matrix inversion, for example.
. Indeed, a grid-parallelogram of area one cannot cover any grid-points except its corners, by Pick’s Theorem. This avoids any mention of matrix inversion, for example. (those that cannot be factored further) are not prime (do not satisfy the implication
(those that cannot be factored further) are not prime (do not satisfy the implication  or
or 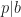 ). The first counterexample that I learned was in the ring
). The first counterexample that I learned was in the ring ![Z[\sqrt{-5}]](https://s0.wp.com/latex.php?latex=Z%5B%5Csqrt%7B-5%7D%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002) in which
in which  . The element
. The element  is irreducible but not prime. I think this counterexample is natural to the number theorist and instructor — having a prior background in quadratic rings — but most unusual to the elementary number theory student. It also leaves the instructor having to convince the student that
is irreducible but not prime. I think this counterexample is natural to the number theorist and instructor — having a prior background in quadratic rings — but most unusual to the elementary number theory student. It also leaves the instructor having to convince the student that  and
and 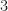 are irreducible. That is probably too difficult for the beginning student. A more elementary example occurs in Hilbert’s monoid
are irreducible. That is probably too difficult for the beginning student. A more elementary example occurs in Hilbert’s monoid  of natural numbers congruent to one modulo
of natural numbers congruent to one modulo 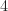 . In this monoid (under multiplication), 9 is irreducible. On the other hand,
. In this monoid (under multiplication), 9 is irreducible. On the other hand, 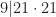 but 9 does not divide 21. Another way to say this is that 441 factors into irreducible in two ways:
but 9 does not divide 21. Another way to say this is that 441 factors into irreducible in two ways:  and
and 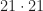 . So this Hilbert monoid might break the student’s false intuition that irreducible elements are prime, and that factorization must be unique.
. So this Hilbert monoid might break the student’s false intuition that irreducible elements are prime, and that factorization must be unique.
 . Thus I have drawn attention to the prime angles (with tick marks on the circumference) and the primes of the form
. Thus I have drawn attention to the prime angles (with tick marks on the circumference) and the primes of the form  in the diagram of Eisenstein integers.
in the diagram of Eisenstein integers.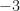 and
and 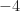 , respectively.
, respectively.
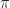 is the decimal expansion
is the decimal expansion 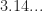 for most students. But this too is incorrect, leading to confusion when students or teachers hear that
for most students. But this too is incorrect, leading to confusion when students or teachers hear that  equals
equals  for the first time. Real numbers are not decimal expansions, nor are rational numbers fractions.
for the first time. Real numbers are not decimal expansions, nor are rational numbers fractions. , I say that
, I say that  kisses
kisses  if
if  or
or  . I call this kissing, because two fractions kiss when their Ford circles kiss; kissing circles have been around for a long time, sometimes called tangent (touching) circles or osculating circles. Kissing fractions are the algebraic counterpart of kissing circles. Kissing fractions leads to more kissing, love triangles, and more. You’ll have to read Chapter 4 to find out. In case you think it is all a love-fest, Chapter 4 also contains material on the construction of the 17-gon and Dirichlet’s approximation theorem.
. I call this kissing, because two fractions kiss when their Ford circles kiss; kissing circles have been around for a long time, sometimes called tangent (touching) circles or osculating circles. Kissing fractions are the algebraic counterpart of kissing circles. Kissing fractions leads to more kissing, love triangles, and more. You’ll have to read Chapter 4 to find out. In case you think it is all a love-fest, Chapter 4 also contains material on the construction of the 17-gon and Dirichlet’s approximation theorem.
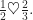 since
since 


{kind=link}